Какие возможности даёт использование дедупликации?
Снижение затрат на хранение данных
Многопоточная глобальная inline-дедупликация позволяет искать повторяющиеся блоки во всех записываемых данных и сохранять только уникальные данные. Это позволяет более эффективно использовать доступное дисковое пространство. В итоге на заданном объёме дискового пространства можно хранить в среднем в 6-12 раз больше данных, что снижает затраты на хранение и обслуживание.
Сокращение окна резервного копирования
Запись только уникальных блоков данных ускоряет процесс резервного копирования, а также передача меньшего объёма данных снижает нагрузку на сеть.
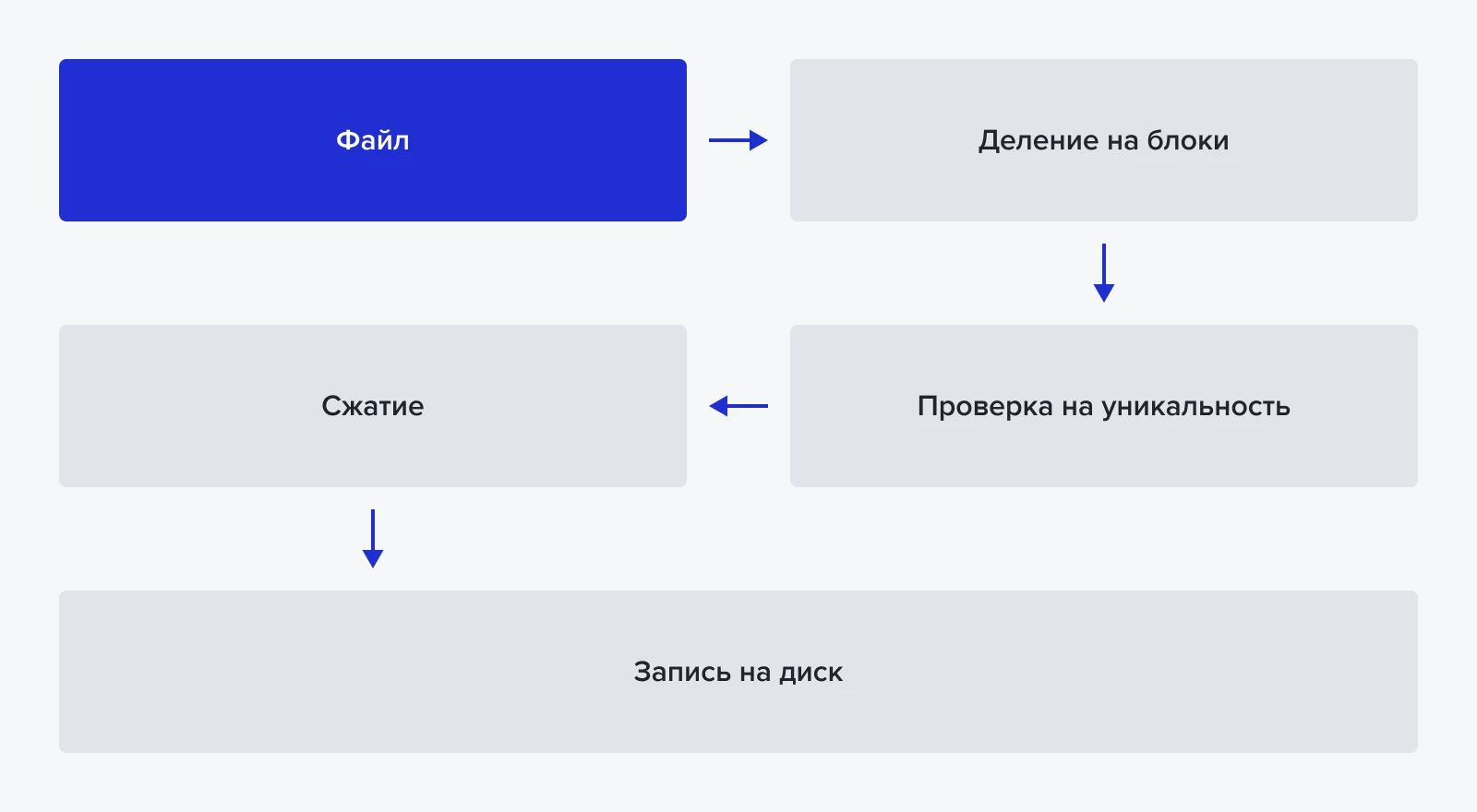
Как работает дедупликация?
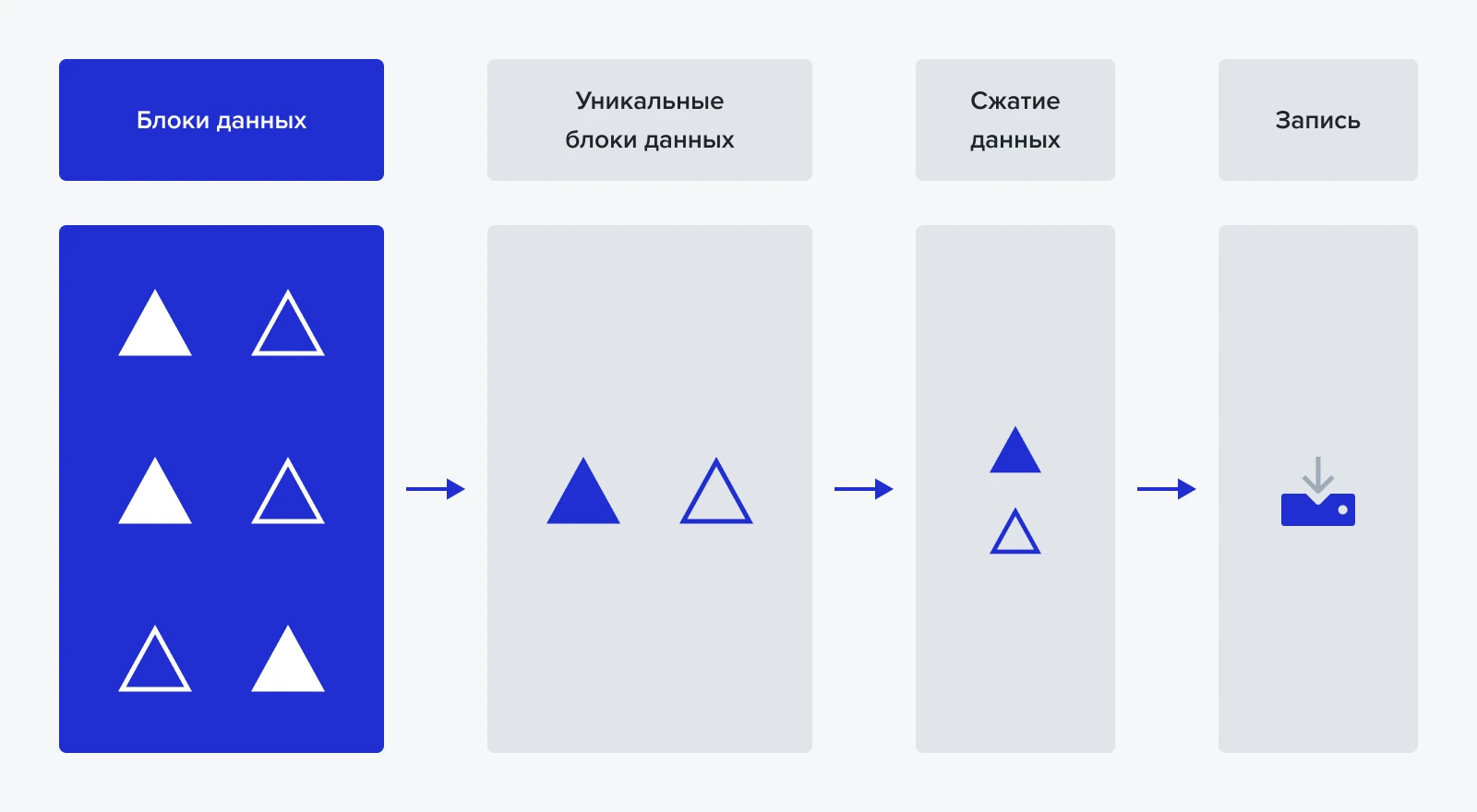
Деление данных по блокам переменной длины
В TATLIN.BACKUP используется разновидность CDC — Content Defined Chunking, то есть дедупликация по блокам различной длины, которая зависит от содержания данных.
Дедупликация данных с блоком переменной длины заключается в том, что перед записью данные пользователя разбиваются на небольшие блоки (чанки) с помощью улучшенного инженерами YADRO алгоритма из семейства CDC, где граница блока определяется на основе хэш-алгоритмов. Такие блоки можно найти в потоке данных независимо от того, какие новые данные были добавлены в любом месте.
Наше улучшение алгоритма CDC состоит в том, что TATLIN.BACKUP разбивает файл на блоки по мере его приёма, даже если запись ведётся параллельно в несколько потоков в одну виртуальную файловую систему. Системе не требуется получать по сети весь файл, как того потребовал бы оригинальный алгоритм CDC.
Расчёт хэшей и поиск дубликатов
После разбиения файла на блоки для каждого из них рассчитывается криптографический хэш, который гарантирует уникальность блока. Сам файл описывается массивами ссылок на блоки. Ссылкой (ключом) и является уникальный хэш. По нему система ищет, какие из новых блоков являются дубликатами ранее уже записанных.
Сжатие по алгоритму ZSTD
Каждый сохранённый блок данных подвергается сжатию с помощью алгоритма ZSTD. Полученные после компрессии блоки упаковываются в контейнеры фиксированного размера и записываются на диск. Компрессия по алгоритму ZSTD обеспечивает сжатие до 2.5:1 в рамках фрагмента.
Дедупликация таким образом осуществляет «глобальное сжатие данных».

